8 聚类[Clustering]
8.1 样本-基因 热图[Sample-Gene heatmap]
方法[Method]
在基因水平进行无监督的层次聚类,使用的数据是所有样本基因的 \(log_2(FPKM+1)\) 。 4984 个基因用于聚类, 筛选条件是 \(1<maximum\{log_2(FPKM+1)\}<20\) 并且标准差 \(sd\{log_2(FPKM+1)\} > 0.3\) 。
Unsupervised hierarchical clustering was carried on \(log_2(FPKM+1)\) across samples. 4984 genes used for clustering, which were selected by \(1<maximum\{log_2(FPKM+1)\}<20\) and the standard deviation \(sd\{log_2(FPKM+1)\} > 0.3\).
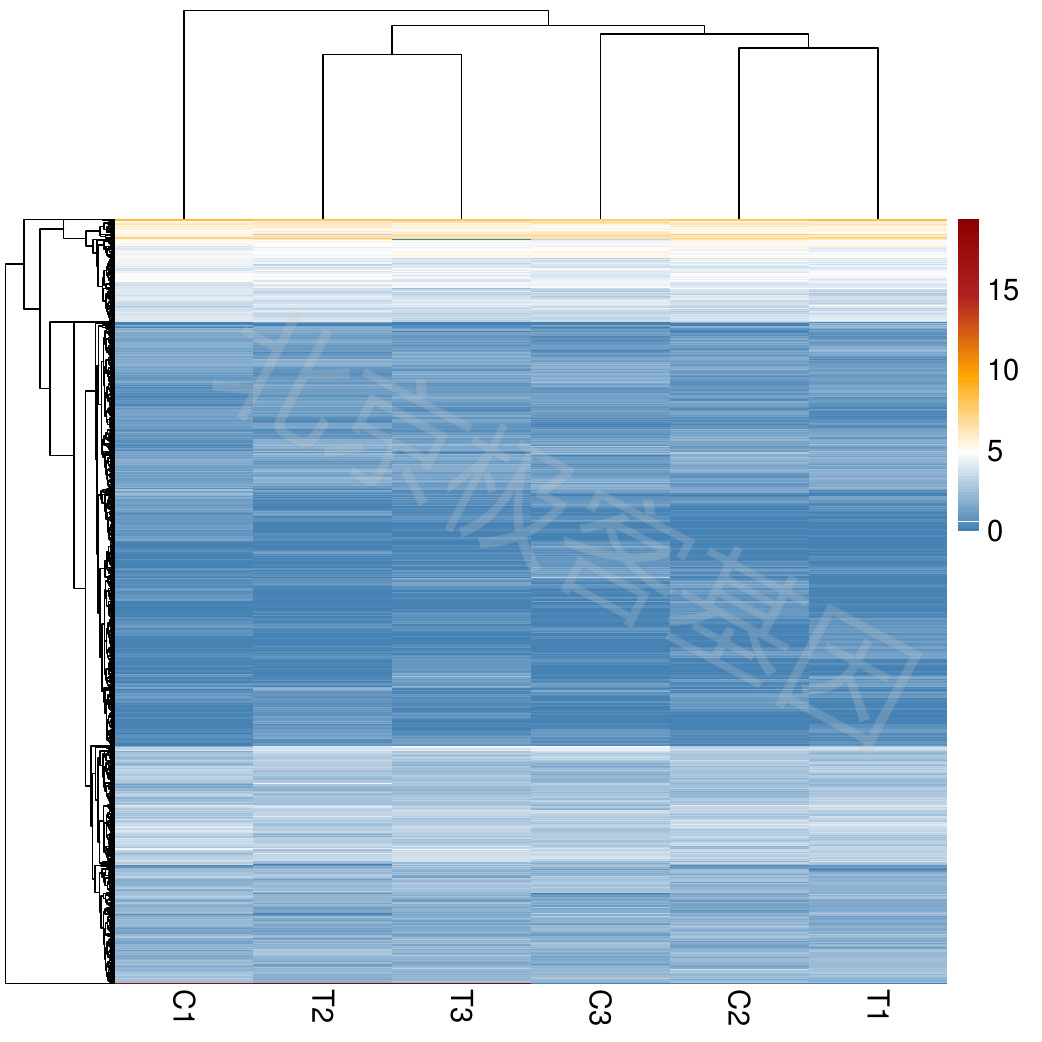
Figure 8.1: Unsupervised clustering (samples-genes)
PDF 文件 : Heatmap.jpg.
- 要阅读热图中详细的基因名称,请参阅较大的视图 PDF PNG.
- 按层次聚类分成12个组 PDF PNG.
- 分组信息 Heatmap_cutree12_GroupInfo.xls.
- 组内信息 Heatmap_cutree12.xls.
- To read the detailed gene names in heatmap, please refer to the larger view PDF PNG.
- To check gene names in sub-groups, a 12-cut view is generated PDF PNG.
- The sub-group information can be found at Heatmap_cutree12_GroupInfo.xls.
- The information about genes in each sub-group can be found at Heatmap_cutree12.xls.
{kind=link}
{kind=link}
8.2 样本-样本 热图[Sample-Sample heatmap]
方法[Method]
在样本水平进行无监督的层次聚类,其中距离定义为 \((1-r^2)\), 其中 \(r\) 是上述所选基因 \(log_2(FPKM+1)\) 的相关系数.
Unsupervised hierarchical clustering was samples, where the distance is defined as \((1-r^2)\), where the \(r\) is the correlation coefficient for \(log_2(FPKM+1)\) on above selected genes.
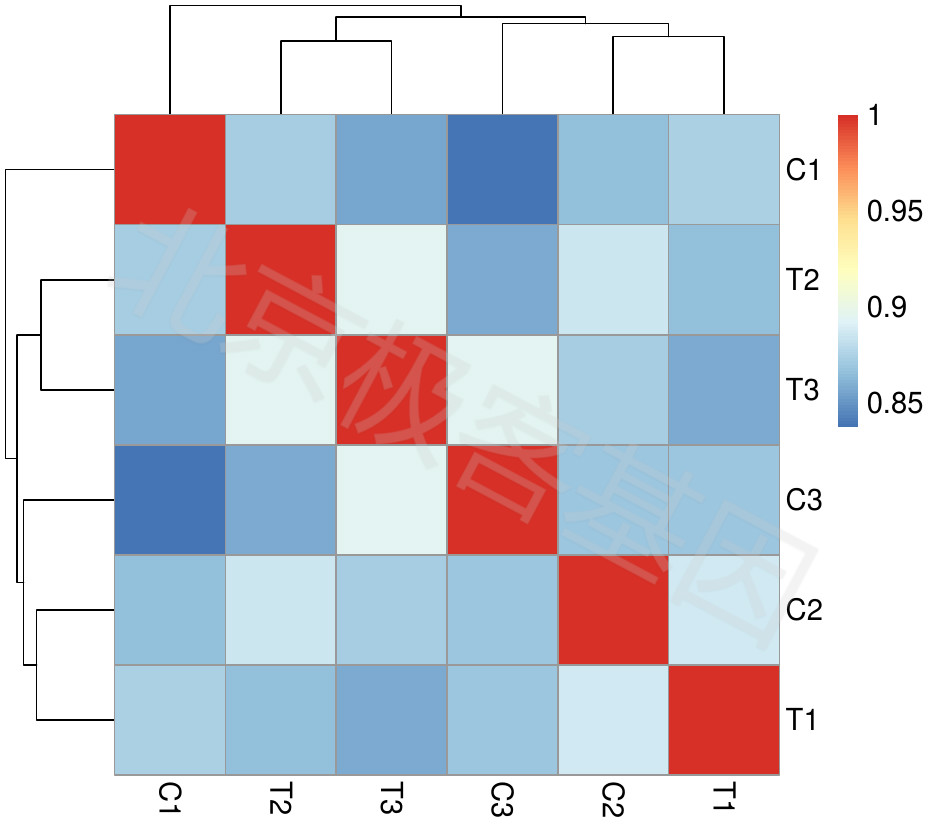
Figure 8.2: Unsupervised clustering (samples-sample)
PDF 文件 : Heatmap_samplewise.jpg.
8.3 差异表达基因热图[Heatmap only for DEG]
方法[Method]
仅使用 \(FPKM>1\) 的差异表达基因进行监督层次聚类 。
Supervised hierarchical clustering was carried only on DEGs (differentially expresed genes) that \(FPKM>1\).
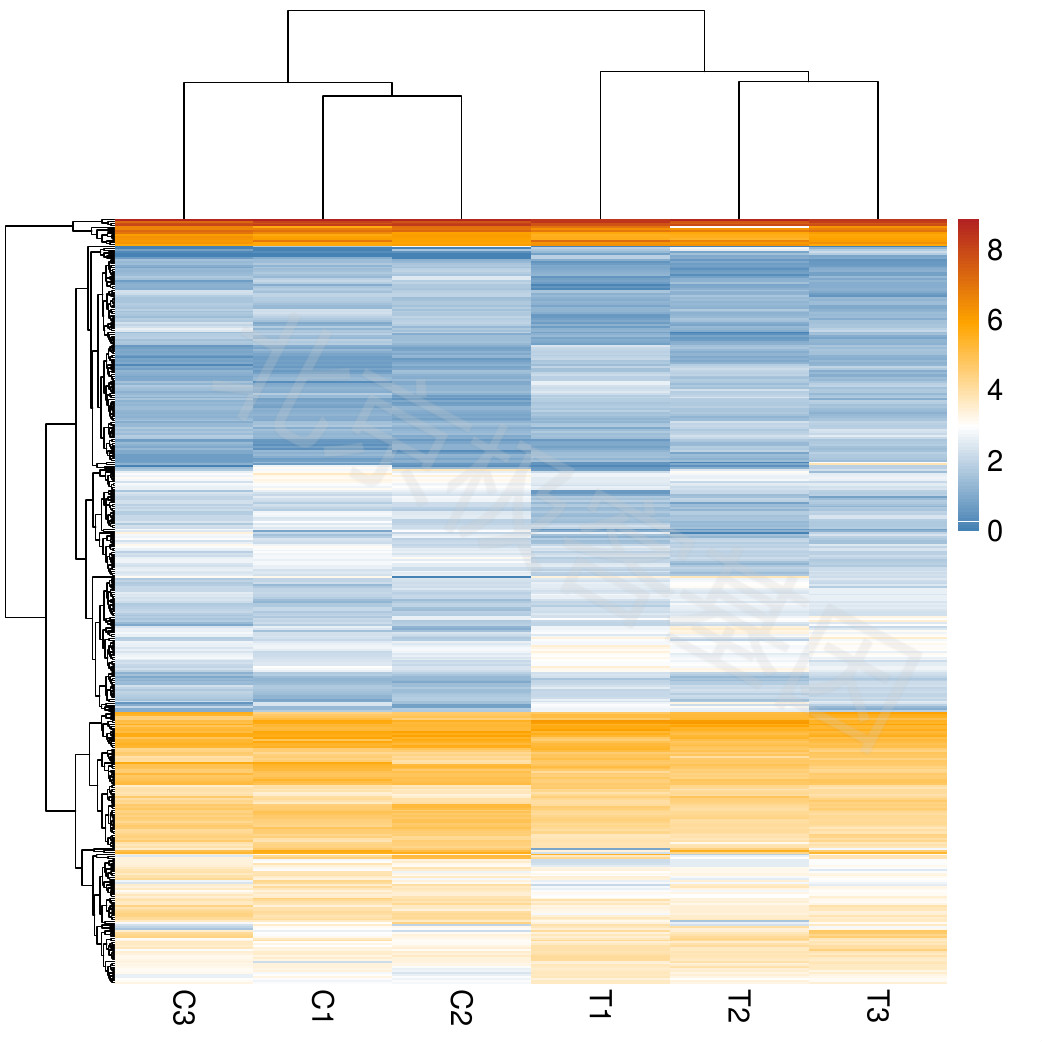
Figure 8.3: Clustering only for DEGs
PDF 版本 : Heatmap_DEG.jpg.
{kind=link}
