10 K-means 分析[K-means analysis]
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
The k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster.
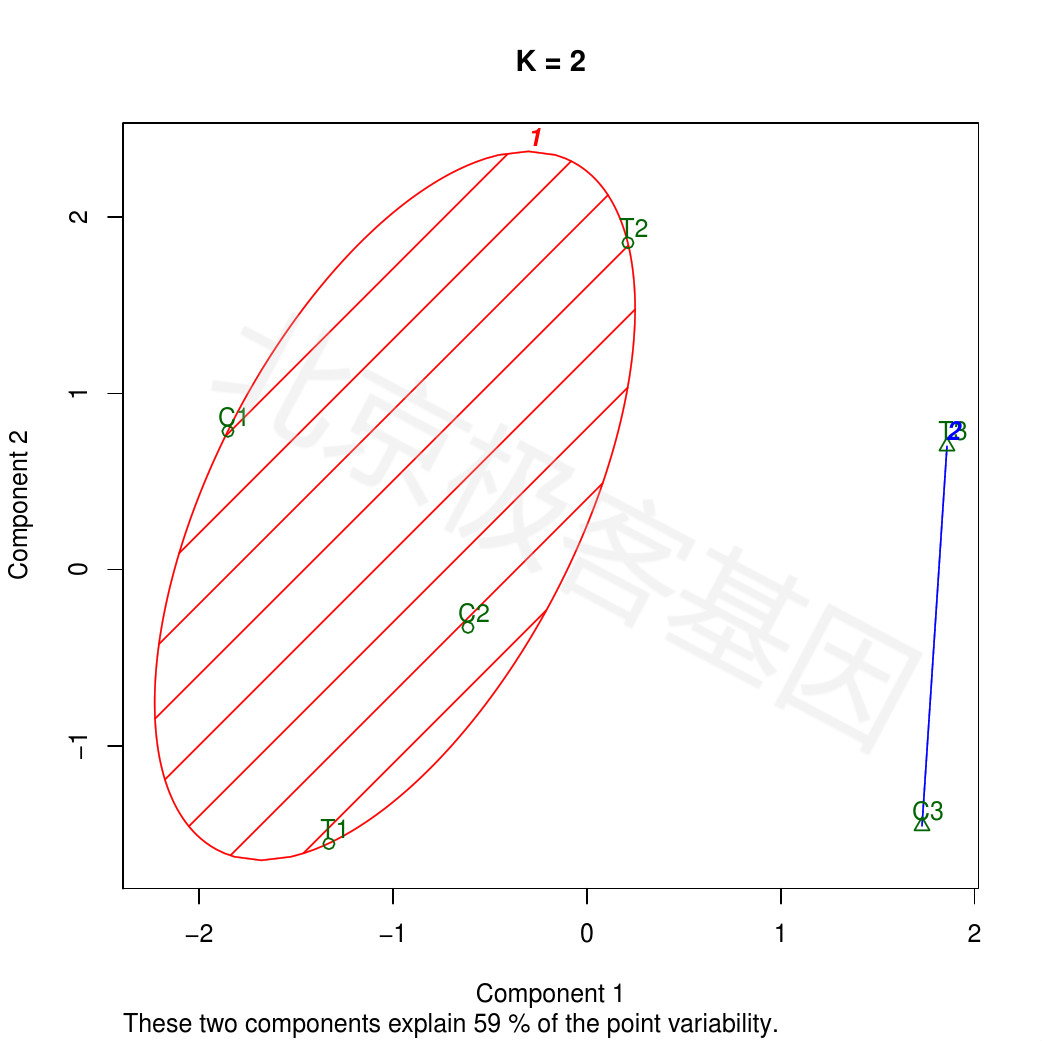
Figure 10.1: K-means analysis: K=2
PDF 文件 : cuffnorm_KMeansClusPlot_K2.jpg.
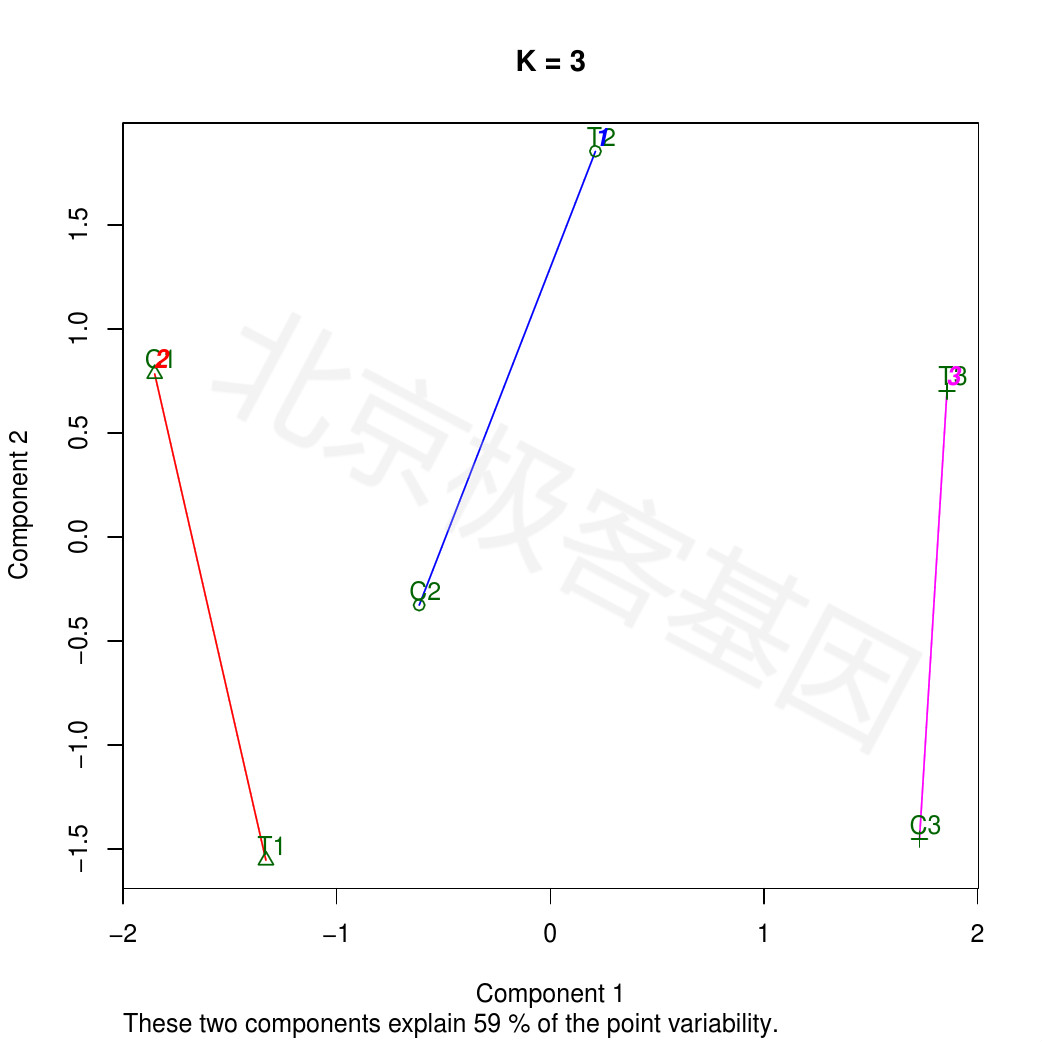
Figure 10.2: K-means analysis: K=3
PDF 文件 : cuffnorm_KMeansClusPlot_K3.jpg.
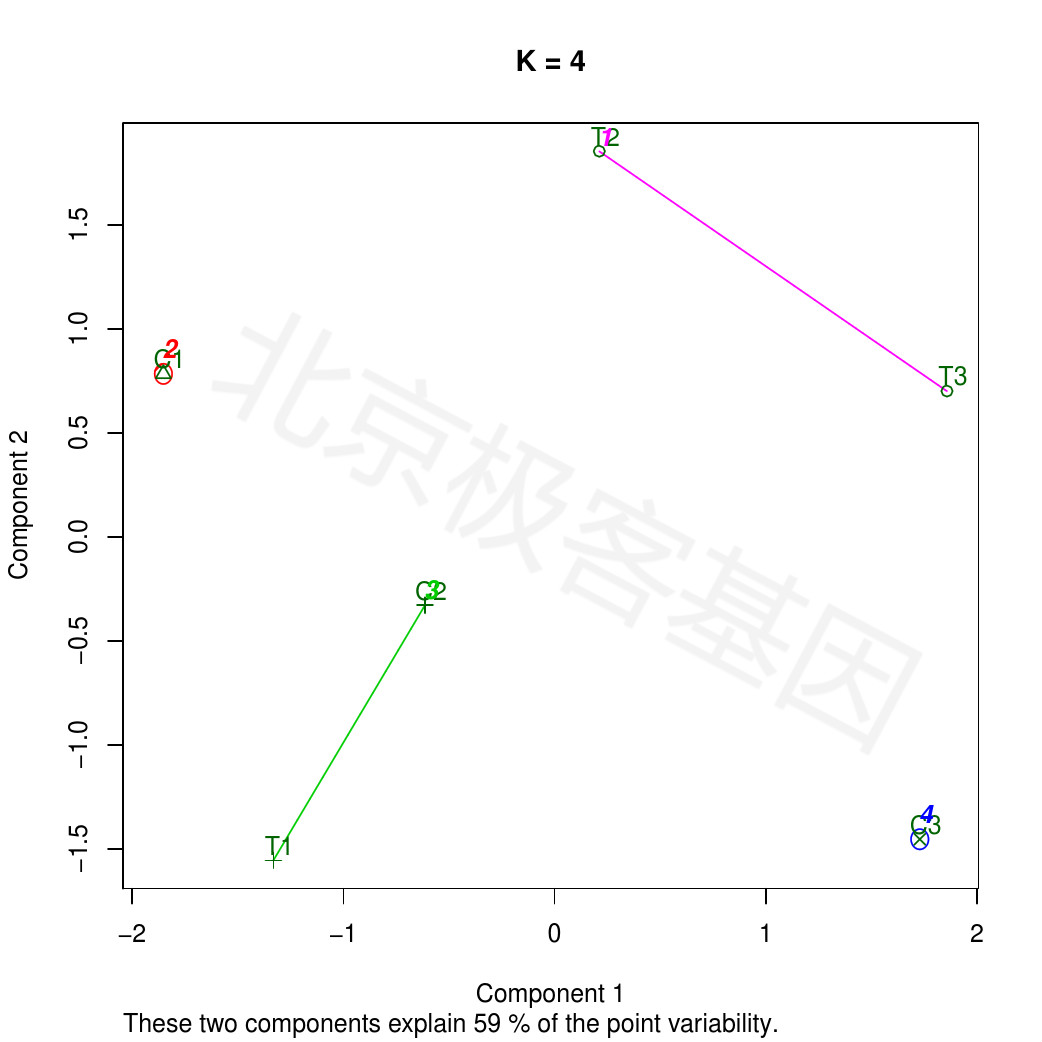
Figure 10.3: K-means analysis: K=4
PDF 文件 : cuffnorm_KMeansClusPlot_K4.jpg.
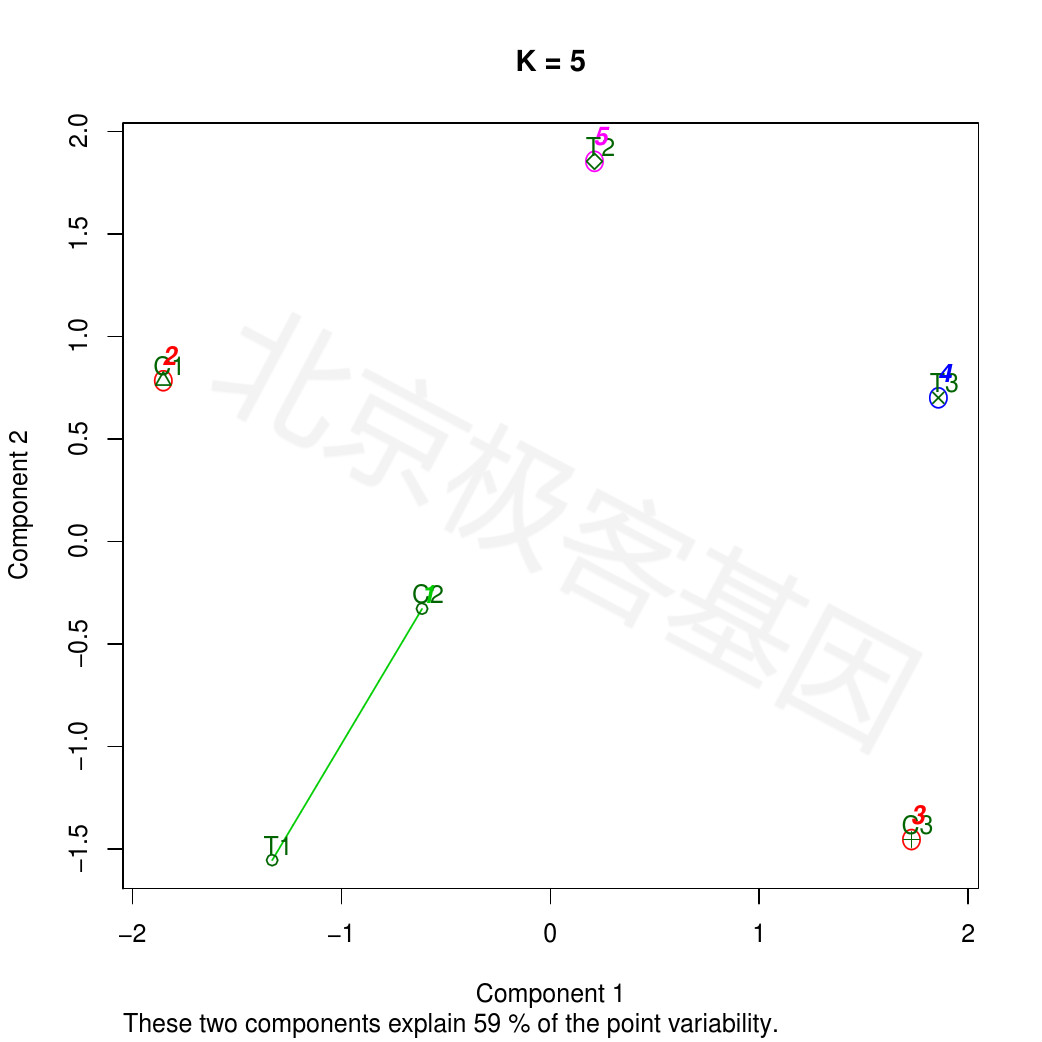
Figure 10.4: K-means analysis: K=5
PDF 文件 : cuffnorm_KMeansClusPlot_K5.jpg.
