9 样本间比较[Compare across samples]
本节通过以转录丰度水平为基础,对样本进行了比较。以多种方法探究样本之间的关系。通过这些比较可以帮助您发现异常样本,反馈实验设计,以及初步检验样本数据与实验设计之间的一致性。
在进行维度汇总的过程中,我们应用了多种降维方法,不同算法的结果略有不同,您可以选用最符合您需要的结果。本章节默认将所有样本纳入分析,并以原始数据中的样本分组为准,若需要调整参与制图的样本及相关参数,请移步极客基因的在线分析平台。我们提供了简单快速的自定义制图工具,无需代码即可绘制出版品质水平的图表。
9.1 样本内转录本数量比较
以下是对各样本中所有表达转录本的数量统计,同时反映样本间的重叠情况。
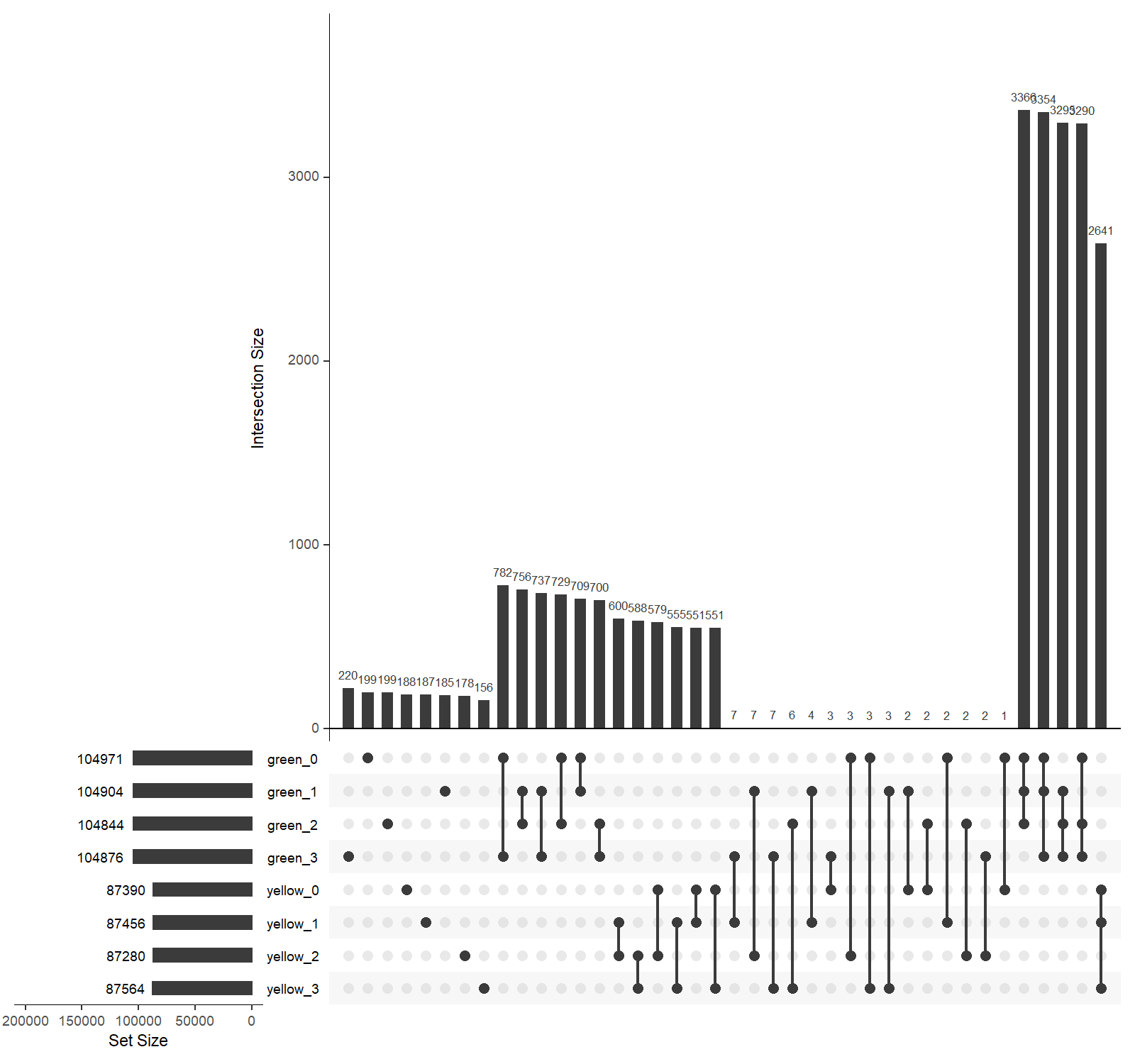
- 左侧条形图表示以拼接所得的转录本为参考,各样本(分组)中有表达的转录本数量。以分组进行排序
- 右侧条形图表示表达转录本在样本间的重叠
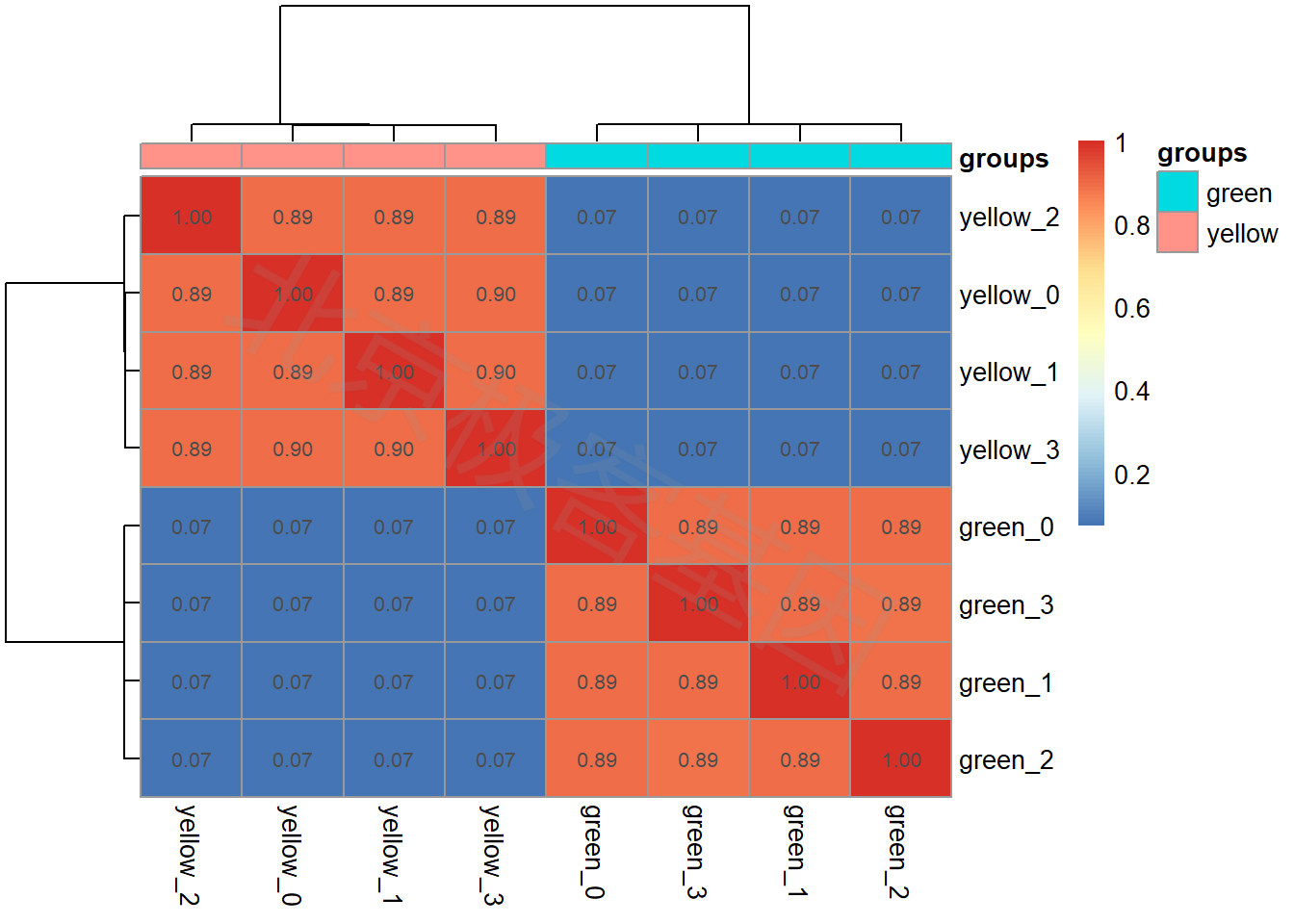
9.2 样本相关性系数
图中每个数据点表示对应样本对之间的相关系数,反映样本在转录本丰度方面的协同性。图中树状结构以样本间的相似性对样本进行归类。
方法[Method]
在样本水平进行无监督的层次聚类,其中距离定义为\((1-r^2)\)。其中r为样本间转录本log2(TPM+1)的相关系数,转录本以sum(log_2(TPM+1))>1进行了过滤。
Unsupervised hierarchical clustering was samples, where the distance is defined as \((1-r^2)\), where the \(r\) is the correlation coefficient for \(log_2(TPM+1)\) of isoforms,filted by \(sum(log_2(TPM+1))>1\).
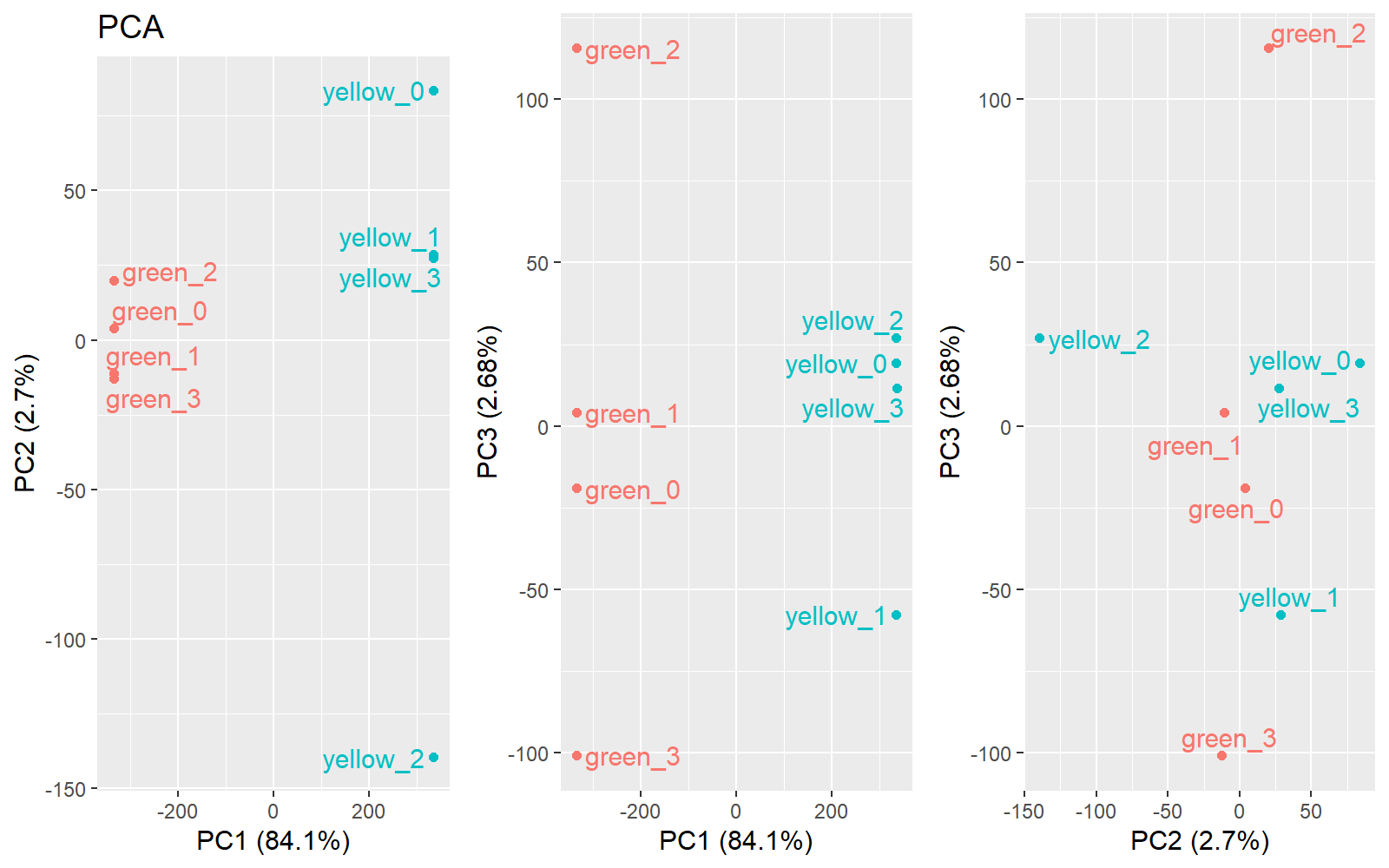
9.3 PCA分析
主成分分析(Principal component analysis,PCA) 是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。 每个点代表一个样本。
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. Each dot represents a sample.
图中颜色显示了样本在元数据(见第一章)中的原始分组。
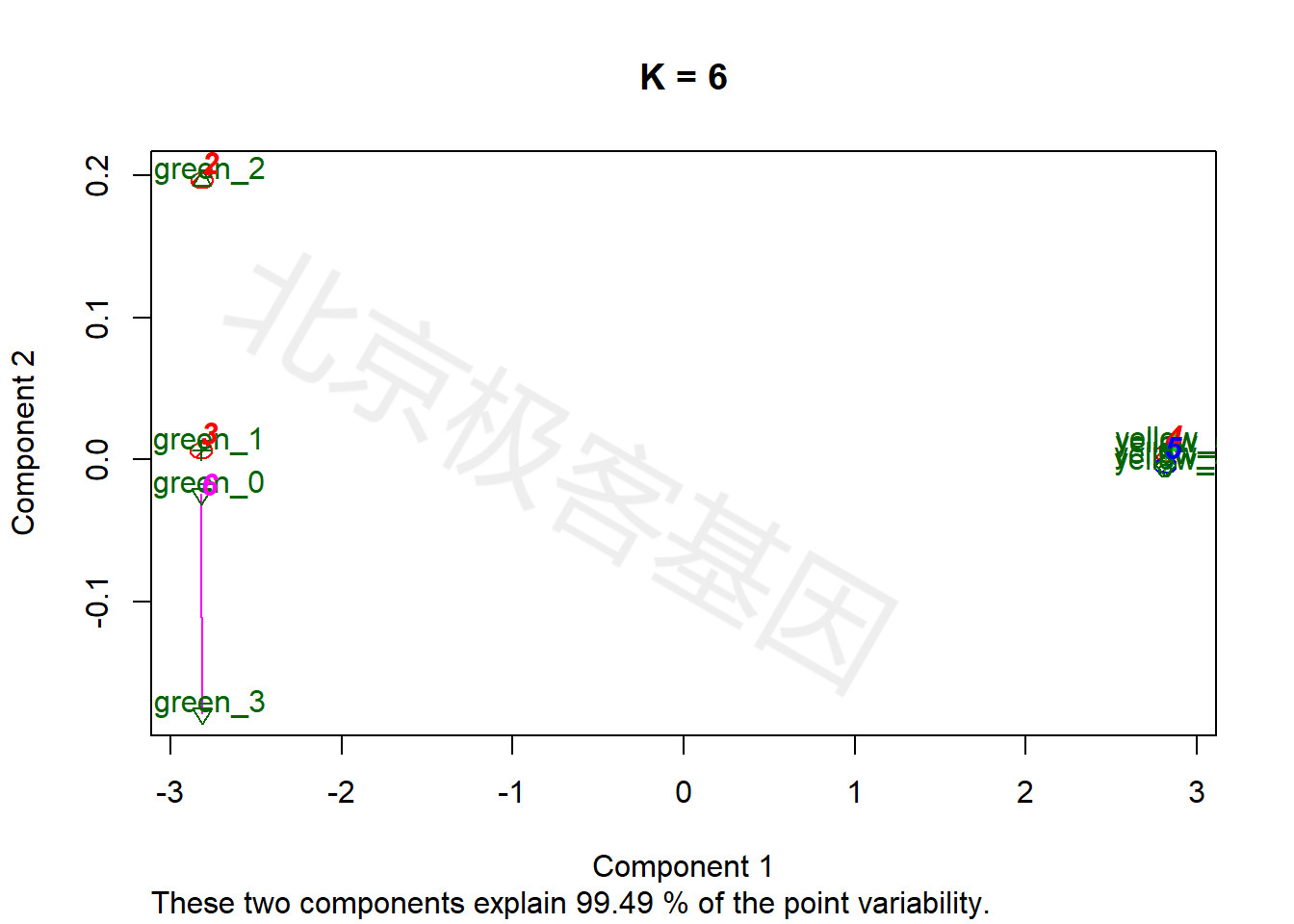
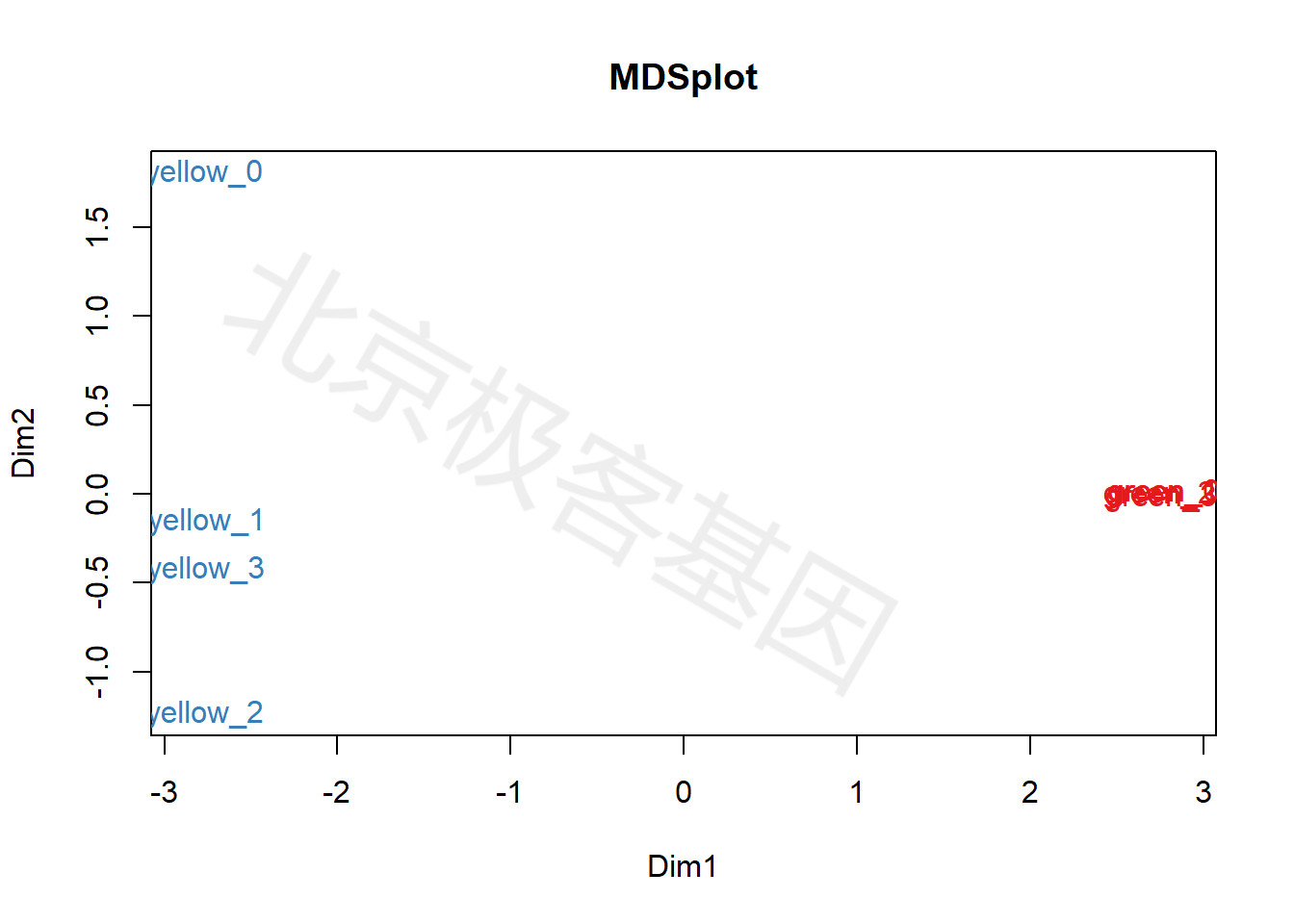
9.4 多维尺度分析(MDS)
多维尺度分析MDS用于反应多个样本间相似(不相似)程度,通过适当的降维方法,将这种相似(不相似)程度在低维度空间中用点与点之间的距离直观表示。MDS与PCA分析相似,均是常用的线性降维方法。
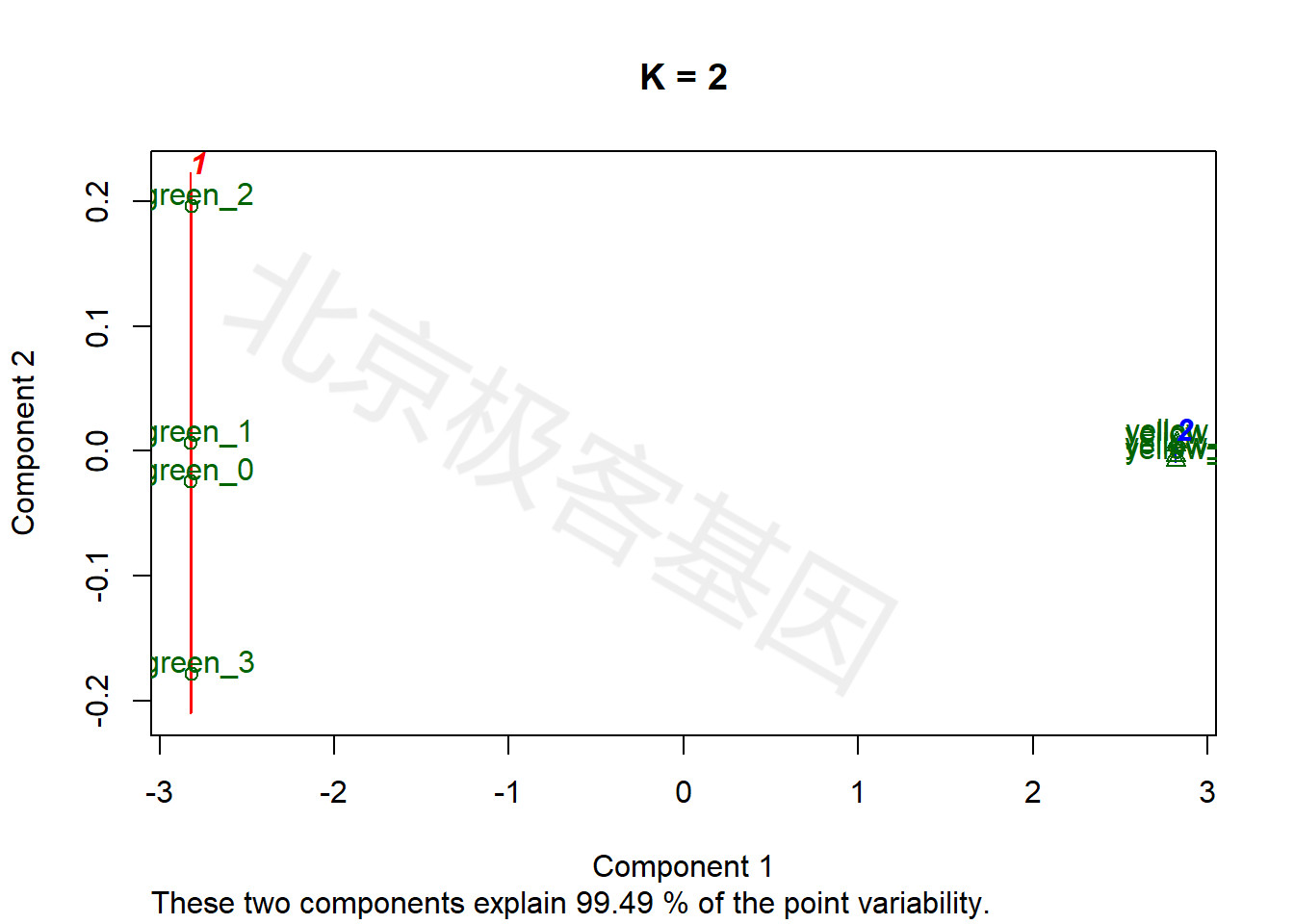
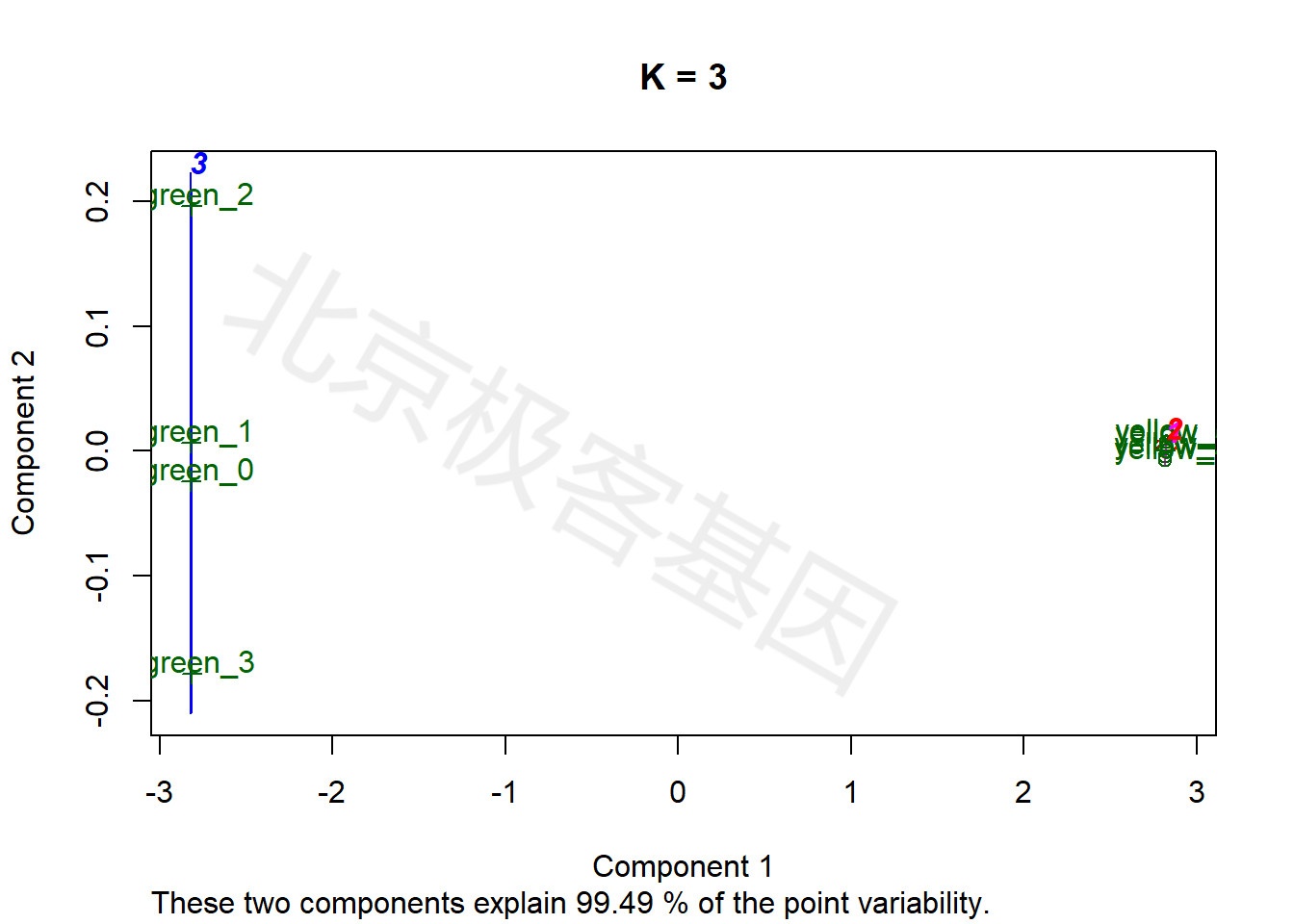
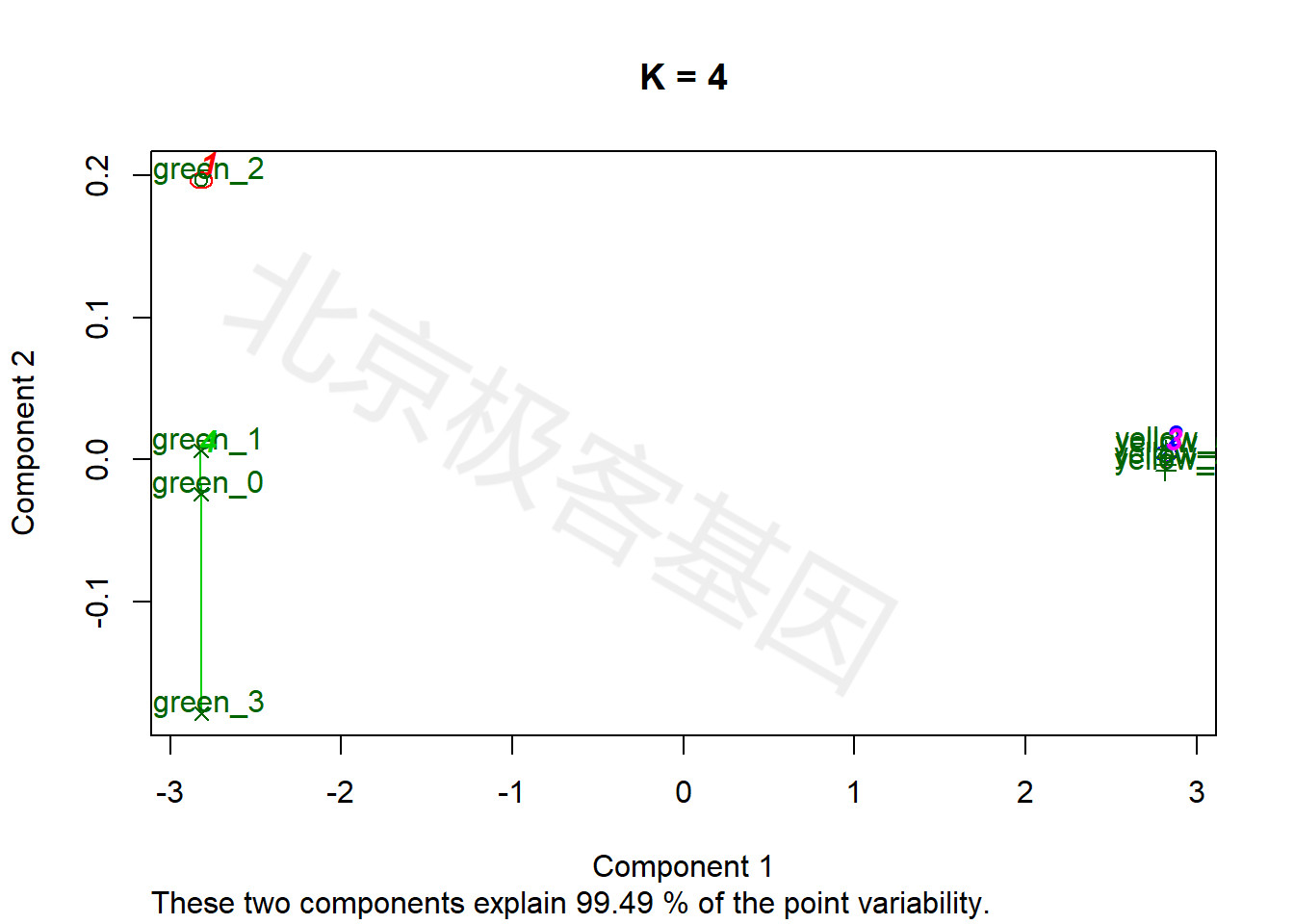
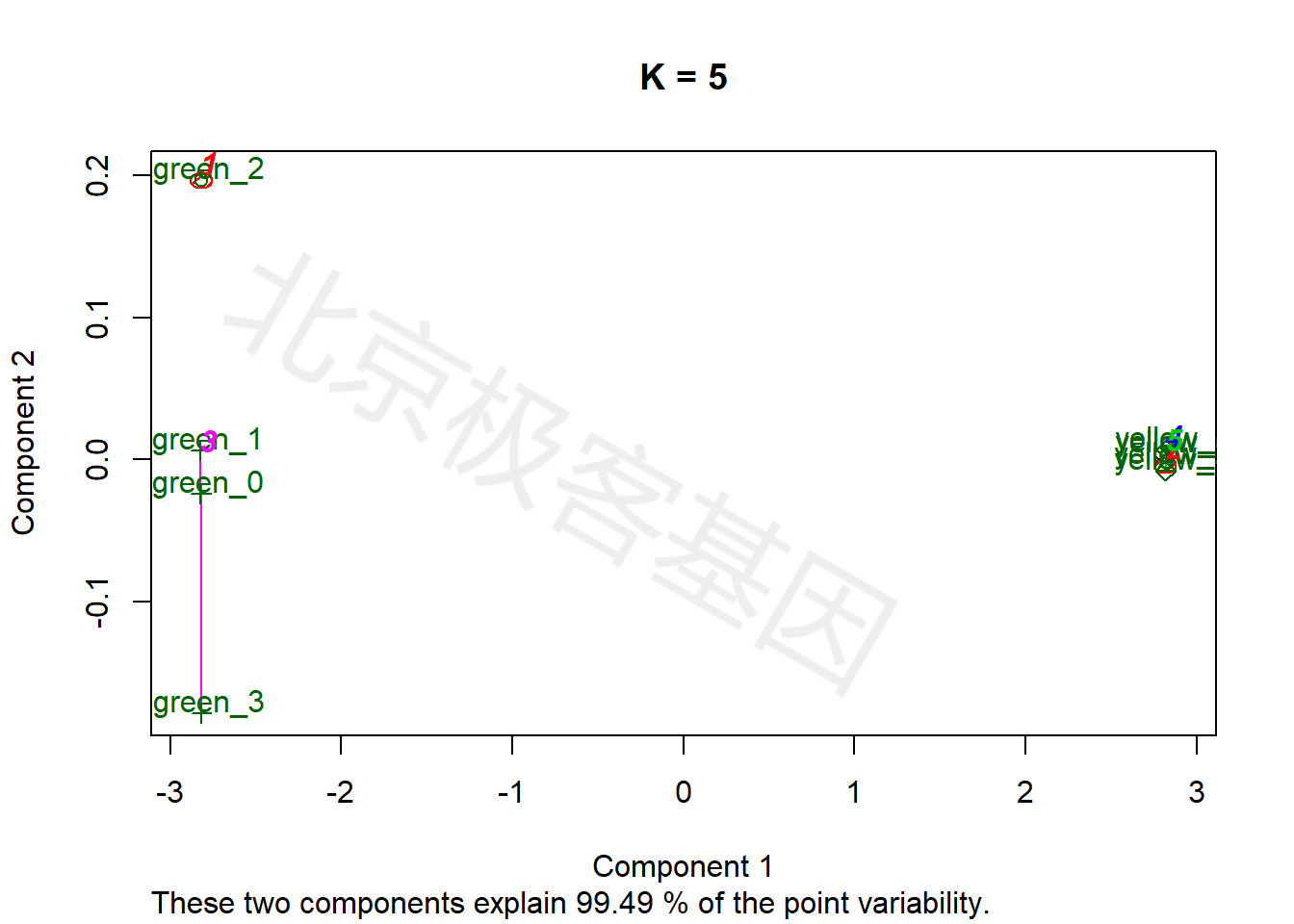
9.5 k-means分析
上述各聚类、降维方法均为无监督方法,即事先不指定样本可以分为多少类别,由算法判断最终的类别数量。相反,k-means为有监督聚类,即事先指定样本应被分为k个类别。
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
The k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster.