4 转录本拼接[Assemble]
方法[Method]
使用Trimmomatic(v0.39)过滤低质量reads。用Trinity(v2.8.5)软件基于过滤后的read是进行转录本的拼接。
Trimmomatic (v0.39) was used to filter low quality reads. Trinity (v2.8.5) software was used to assemble the transcripts based on the filtered reads.
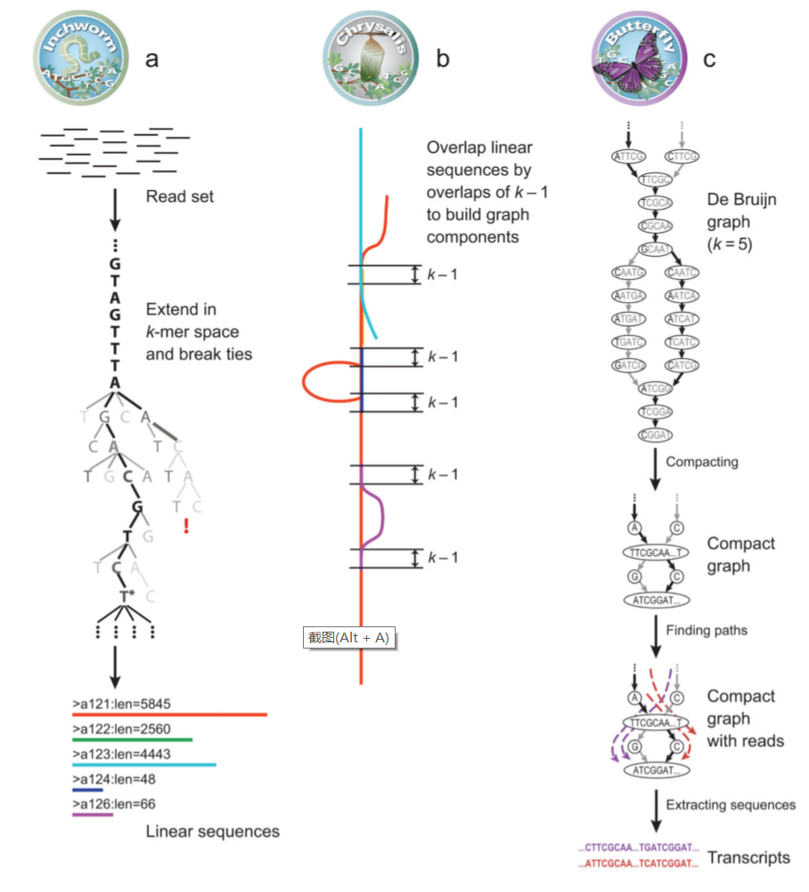
Trinity是由Broad Institute 和Hebrew University of Jerusalem开发的转录组de novo组装软件,由三个独立的软件模块组成:Inchworm Chrysalis和Butterfly,三个软件依次处理大规模RNA-seq的reads数据,得到拼接转录本。
Trinity将序列数据划分成许多个独立的de Bruijn图,每个图代表给定基因或位点的转录复杂性,然后独立处理每个图以提取全长剪接同工型,并梳理区分从旁系基因衍生的转录本。
Trinity, developed at the Broad Institute and the Hebrew University of Jerusalem, represents a novel method for the efficient and robust de novo reconstruction of transcriptomes from RNA-seq data.
Trinity partitions the sequence data into many individual de Bruijn graphs, each representing the transcriptional complexity at a given gene or locus, and then processes each graph independently to extract full-length splicing isoforms and to tease apart transcripts derived from paralogous genes.
4.1 组装结果统计[Assembly result statistics]
根据reads中的序列重复,Trinity组建重叠群,这样的转录簇被宽泛的称为“基因”。每个gene可能对应多个转录本isoform。
Based on sequence repeats in reads, Trinity forms contigs. Such transcription clusters are broadly referred to as “genes.” Each gene may correspond to multiple isoforms.
拼接所得基因数量(Total trinity ‘genes’): 139188
拼接所得转录本数量(Total trinity transcripts):189471
拼接结果GC含量(Percent GC): 43.25
Reads经过拼接得到若干条序列。中间没有gap的一段连续序列称为contig;如果所得序列中间有已知长度的gap,则称为scaffold。
Reads are spliced to several sequences. A continuous sequence without gaps in it is called contig.If there is a gap of known length in the obtained sequence, it is called scaffold.
4.2 拼接转录本序列[Assembled transcript sequence]
组装转录本[Assembled Transcript] : Trinity.fasta
基因-Isoform对应关系[Map of Isoform to GENE] : gene_trans.map
4.3 转录本序列ID格式说明[Description transcript sequence ID]
组装转录本文件“Trinity.fasta”为组装后的转录本,举例如下:
>TRINITY_DN1000_c115_g5_i1 len=247 path=[31015:0-148 23018:149-246] AATCTTTTTTGGTATTGGCAGTACTGTGCTCTGGGTAGTGATTAGGGCAAAAGAAGACAC ACAATAAAGAACCAGGTGTTAGACGTCAGCAAGTCAAGGCCTTGGTTCTCAGCAGACAGA AGACAGCCCTTCTCAATCCTCATCCCTTCCCTGAACAGACATGTCTTCTGCAAGCTTCTC CAAGTCAGTTGTTCACAGGAACATCATCAGAATAAATTTGAAATTATGATTAGTATCTGA TAAAGCA
序列名称TRINITY_DN1000_c115_g5_i1表示该转录本来自编号为“TRINITY_DN1000_c115”的Reads簇,gene “g5”,isoform “i1”,序列长度247。
4.4 转录本长度相关指标[Transcription length related indicators]
N50为反映拼接序列长度情况的常用指标。将所有序列按照长度降序排列,按排列顺序对序列长度进行加总,加总长度达到所有碱基数量50%时,最后一个被加总的片段长度即为N50。N10~N90同理。
N50 is a commonly used indicator to reflect the length of the splicing sequence. All fragment are arranged in descending order of length, and the sequence lengths are summed in the order of the arrangement. When the total length reaches 50% of the total number of bases, the length of the last aggregated fragment is N50. The same goes for N10 ~ N90.
以所有转录本进行统计[Stats based on ALL transcript contigs]:
| Contig N10 | 4172 |
| Contig N20 | 2846 |
| Contig N30 | 2143 |
| Contig N40 | 1621 |
| Contig N50 | 1178 |
| Median contig length | 335 |
| Average contig | 674.77 |
| Total assembled bases | 127849154 |
以每个‘gene’中的最长转录本进行统计[Stats based on ONLY LONGEST ISOFORM per ‘GENE’]:
| Contig N10 | 4172 |
| Contig N20 | 2846 |
| Contig N30 | 2143 |
| Contig N40 | 1621 |
| Contig N50 | 1178 |
| Median contig length | 335 |
| Average contig | 674.77 |
| Total assembled bases | 127849154 |
在从头拼接转录本中,因表达量较低以及测序错误等原因,会出现部分拼接不全或拼接错误的低质量的转录本,这些转录本通常表现为长度短,丰度低。这些低质量的转录本会直接影响N50指标,因而对转录本按照丰度进行从高到底排序,挑选转录水平较高的前百分之x进行N50统计(ExN50),能够更好地反应转录本的长度状况,并且根据该指标能够初步判断测序数据量是否充足。
